
In a previous post, I laid out some time-series issue I want to explore. I also simulated some data in order to start thinking about how to model seasonal data when the seasonal patterns could be changing.
Just as a reminder, my main motivation here is trying to conceptualize how to deal with seasonal time-series data when I want to test whether a policy implemented in some time, 
The two post dealt independently with the issues of stationarity of time-series data, seasonality, and autocorrelated residuals. In this post I want to address seasonal unit roots/stochastic seasonality
1. Stochastic Seasonality
I haven’t completely grasped how all these things fit together yet but, in the interest of completeness, I wanted to talk about them. Hylleberg (1986) describe three main types of seasonality in time-series processes:
A. Deterministic seasonal processes
I’m not super stoked about the term ‘deterministic’ being applied in an econometric sense…but who am I to argue with Sven Hylleberg? Most pros seem to agree that the familiar seasonal dummy variable regression:


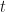
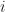
describes a ‘deterministic’ seasonal model.
B. Seasonal stochastic stationary processes
It was a lot easier for me to accept the term ‘deterministic seasonality’ above once I processed the concept of stochastic stationary seasonality. Let 

denotes the lag operator such that
. If
for our monthly seasonal process
is the seasonal AR polynomial
is the seasonal MA polynomial
As long as the roots of these seasonal AR,MA polynomials lie outside the unit circle then the process is covariance stationary.
I know that’s a bit formal but sometimes formality is good. In this case it helped me see the difference between stochastic stationary seasonality and deterministic seasonality in a way that was hard for me to visualize from intuitive explanations.
The easiest way for me to process the difference between stationary stochastic seasonality and deterministic seasonality is to think about the optimal one-period ahead forecast. In the seasonal dummy variable regression our best guess at next January’s value is the same no matter what year we are in. The optimal prediction for the value in season 


In the seasonal AR(1) model our best guess at next January’s value depends on our most current January value and our past errors:

Also, for the sake of completeness, I should mention that the same process can have seasonal and non-seasonal AR and MA components. Here’s a set of lecture notes from a time-series class at Penn State that I think provides some cool examples of how to combine seasonal and non-seasonal components in ARIMA-type modes.
In grappling with the notion of stochastic seasonality I found it kind of helpful to draw some pictures…kind of like I did here for stationary, trend stationary, and non-stationary series. First, I simulated two series each with 120 values (10 years of monthly data) with the following qualities:
- the first series is a seasonal AR(1) process (by that I mean the current value in the series is related to the value 12 months ago) with an autoregressive coefficient set to 0.9.
- the second is a non-seasonal AR(1) process (the current value is related to the previous value) with the autoregressive coefficient set to 0.9.
I generated these two series with the code below
require(stats) #use the arima.sim function to simulate: # 1). a seasonal AR(1) process with monthly frequency seasonal.ar1.sim <- arima.sim(list(order = c(12,0,0), ar = c(rep(0,11),0.9)), n = 120) # 2). a basic AR(1) process with the same ar parameter for comparison ar1.sim <- arima.sim(list(order = c(1,0,0), ar = 0.9), n = 120) #combine them for plotting s.tmp <- data.frame(rbind(data.frame(t=c(1:120),x=c(seasonal.ar1.sim),type="Seasonal AR(1)"), data.frame(t=c(1:120),x=c(ar1.sim),type="Non-Seasonal AR(1)"))) #plot the seasonal AR(1) and the regular AR(1) ggplot(s.tmp,aes(x=t,y=x)) + geom_line() + facet_wrap(~type)
And the resulting plot looks like this:
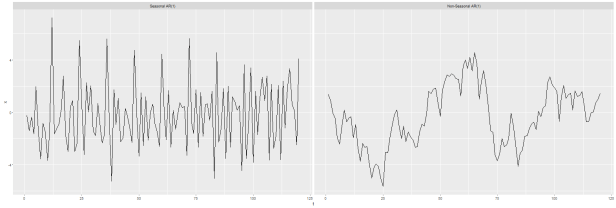
Note that the non-seasonal AR(1) process has the familiar trappings of a stationary series: it wanders around but it looks like it wanders around a pretty stable mean…it moves around 0 but always eventually tends back toward it. The seasonal AR(1) process has the same look of stationarity with the added feature that it appears to repeat some patterns on regular intervals.
The next thing I wondered was how one would identify deterministic versus stochastic seasonality in real world data…data that weren’t generated from a process with known features. Because if I have monthly data and the seasonality is important then, if I go to plot the data, I’ll probably observe some form of peaks and troughs repeating on 12 period cycles. If the seasonality is deterministic those peaks and troughs should be about the same if I’m comparing same-month-different-years. If the seasonality is stationary stochastic then the peaks/troughs should be in about the same places but will tend to have different magnitudes. Since, in my experience, real world data tends exists in the grey area between easily, visually identifiable patterns, I thought an empirical test would be best.
My reasoning here is that, if the monthly data are seasonal, then both the dummy variable model and the seasonal AR(1) model will have merit…but if the seasonality is stochastic then the seasonal AR(1) model should perform better than the dummy variable regression. I checked this by running both models over the data simulated from the seasonal AR(1) process and compared the root mean squared error of the in-sample prediction (the fitted values):
#add a month column
s.tmp$month <- rep(c('jan','feb','mar','apr','may','june','july','aug','sept','oct','nov','dec')
,10)
#run the dummy variable model with the seasonal AR(1) data
det.season <- lm(x~factor(month),
data=s.tmp[which(s.tmp$type=="Seasonal AR(1)"),])
#fit a seasonal AR(1) model to the simulated data
tsx <- s.tmp$x[which(s.tmp$type=="Seasonal AR(1)")]
tsx <- ts(tsx,start(c(2000,12)),frequency=12)
ar1.season <- arima(tsx,
order=c(0,0,0),
seasonal=list(order=c(1,0,0),period=12))
#Compare the RMSE of the dummy variable regression v. the seasonal AR(1) model
# for modeling the simulated seasonal AR(1) data
lm.df <- tbl_df(data.frame(y=s.tmp$x[which(s.tmp$type=="Seasonal AR(1)")], yhat=det.season$fitted.values)) %>%
mutate(error.sq=(y-yhat)^2) %>%
summarise(mean.errorsq=mean(error.sq)) %>% mutate(RMSE=sqrt(mean.errorsq))
summary(ar1.season)
Call:
arima(x = tsx, order = c(0, 0, 0), seasonal = list(order = c(1, 0, 0), period = 12))
Coefficients:
sar1 intercept
0.9047 -0.1889
s.e. 0.0306 0.6043
sigma^2 estimated as 1.153: log likelihood = -189.05, aic = 384.1
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.05575138 1.073729 0.8386037 -110.4396 218.0293 0.2553908 -0.08889676
lm.df
Source: local data frame [1 x 2]
mean.errorsq RMSE
(dbl) (dbl)
1 1.595846 1.263268
And the dummy variable regression model estimated with OLS has a RMSE of 1.26 compared to the seasonal AR(1) model with a RMSE of 1.07…so I’m happy.
Obviously there are other ways to compare models and I don’t usually advocate using one single model fitting criteria as the ‘final word’…but, in this case, I’m just looking to confirm or overturn my suspicions about what should happen by modeling a stationary stochastic seasonal process with a model that the time-series literature uses to describe deterministic seasonal processes.
C. Processes with (a) seasonal unit root(s)
Here’s where the mathematical shit kinda hits the fan and I’d prefer to go back to a slightly less formal treatment. First, to fix terms, in this post I generated a random walk process by simulating:


One consequence of a unit root (unit roots are more complicated than this but I don’t want to write out a giant sequence of lagged polynomials here), is that the AR(1) model,

has 
The random walk process is funky because, in contrast to the stationary series, it wanders around in unpredictable ways. If our series has a seasonal unit root, it means the seasonal component(s) is/are changing across time in ways that are hard to predict.
I’m going to admit here that I still haven’t really wrapped my head around seasonal unit roots because they mess with the dynamics of a seasonal series in ways that make it difficult to give a simple, intuitive example of what a seasonal unit could look like. However, I’m pretty sure (but cannot prove), that one example of a seasonal unit root is a process where the seasonal peak is changing through time. So, for example, if climate change is pushing the peak season for catching some species of fish (maybe population density is related to water temperature or something I don’t know) later in the year then several years worth of monthly landings data might exhibit seasonal unit roots.
Some of the seminal papers on testing for seasonal unit roots are listed below…just a warning: they are pretty heavy on pyro-technics and pretty light on intuition:
And just because I don’t like to walk away from a topic without at least trying to draw a picture. Here is my attempt at trying to visualize
This ain’t the prettiest picture but it’ll work. I generated a process that initially tends to peak around late summer in August. I let the process evolve, shifting towards a process that is still seasonal but tends to peak much earlier in the year (around April).

#try this a different way, start with a deterministic seasonal process like series 2
# here we have some monthly landings distributed throughout the year with a peak around
# late summer early fall. We might imagine a climate process that, because it is tending to
# get warmer earlier in the year, fishing activity is tending to move toward the late winter/spring months.
# the following code generates a process that transitions from a seasonal summer peak to a seasonal
# early spring peak
lbs <- c(200,250,250,300,300,325,325,350,325,325,300,300)
phi <- c(1.02,1.02,1.03,1.02,1.02,0.98,0.98,0.98,0.98,0.985,0.98,0.99)
data <- data.frame(year=rep(2000,12),month=c(1:12),lbs=lbs)
for(t in 2001:2009){
eps <- rnorm(12,0,12)
lbs <- (lbs*phi) + eps
dnow <- data.frame(year=rep(t,12),month=c(1:12),lbs=lbs)
data <- rbind(data,dnow)
}
data$date <- as.Date(paste(data$year,"-",data$month,"-","01",sep=""),format="%Y-%m-%d")
data$t <- c(1:120)
ggplot(data,aes(x=t,y=lbs))+geom_line() + geom_point() + geom_vline(xintercept=c(1,13,25,97,109),color="red") +
annotate("text",x=13,y=375,
label=as.character("Jan 01")) +
annotate("text",x=25,y=375,
label="Jan 02") +
annotate("text",x=97,y=375,
label="Jan 08") +
annotate("text",x=109,y=375,
label="Jan 09")
It’s worth noting that what I’ve done here is equivalent to a linear model with seasonal dummy variables and time-varying coefficients. Consider the system:
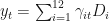
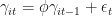
This probably isn’t the best example of stochastic non-stationary seasonality since it is kind of built on the deterministic seasonality model…but I wanted something here that would be i) easily identifiable as seasonal and ii) dynamic with respect to the nature of that seasonality. True, stochastic, non-stationary seasonality, in my experience can be hard to visualize as seasonal since the relative position of the seasonal value can be chaotic owing to the non-stationarity.
