We are truly living in remarkable times. There is so much data and so many tools to turn that data into useable/interesting/insightful information it blows my mind on an hourly basis. I wish I was a bigger part of pushing this revolution forward…but I’m not…I’m kind of a free rider.
I resolved earlier this year to be more adventurous with my data relationships. As an economist, I’m kind of used to seeing data in the same format…for resource economists this usually means dependent variables that are things like, number of fishing trips per fisherman, total annual pollution per energy production firm, growth rate of a timber stand, etc. Independent variables are often things like prices, unemployment rates, population densities, etc.
I don’t tend to work a lot with text data…but I have a vague sense that there are some really cool applications involving data of this type. Empirical Anthropologists and Political Scientists always seem to be pumping out cool looking word clouds or other neat looking sentiment analyses.
The other day I went in search of some data I could use to familiarize myself with stuff like content analysis and sentiment analysis. I found the following posts on the twitteR package which, among other things, allows one to pretty easily search for tweets meeting certain criteria and download them.
- http://www.r-bloggers.com/setting-up-the-twitter-r-package-for-text-analytics/
- http://www.r-bloggers.com/mapping-twitter-followers-in-r/
- http://www.r-bloggers.com/mapping-twitter-followers-in-r/
I used the first link to get a data pipeline between Twitter and R set up in about 20 minutes. HOLYFUCKINGSHIT! I should be used to the awesome power of the R machine by now but every once in a while, like now, I come across something that really makes me feel like I’m not doing enough with my life.
Basically, you just have to go to Twitter’s app page and register an app with them (I called mine the Mamultron2000) and they give you an API key and a bunch of other shit that you can use to search their data.
Note: apparently Twitter is kind of a bunch of bitches about their data and they will only let you get the most recent week’s worth of results for a particular search and they also limit you in some other search capacities…I’ll talk about one of those below.
As a first-pass at getting the hang of this tool, here’s what I did:
- used the getFollowers() functionality from the twitteR package to pull data on all the Twitter users currently following @NOAA Fisheries (my employer).
- this function returns a list. I cleaned up the list a little and coerced it to a data frame
- cleaned up the locations in that dataframe
- used the geocode() function from the ggmap package to georeference the text locations
- used the ggmap package to display the location of followers
Some things I’ve learned that geocode() can deal with:
- ‘Texas Girl’…I don’t know where Texas Girl lives but the Google Maps API will at least put this user in the middle of Texas…seems reasonable.
- ‘3oh3 Colorado’…geocode won’t put this user directly in ‘The 303’ as it were but it will at least place them in Colorado which is cool.
Some wonky things that I don’t have a good batch-type solution for:
- “From Texas living in VOlnation!”….I’m pretty sure this user means to convey that he/she is originally from Texas but is currently residing in Tennessee….not much I can do about this except maybe change the entry by hand.
- ‘Worldwide from Oregon’…geocode puts this guy in Oregon…I’m not convinced (s)he is tweeting from Oregon but I’m not sure what could be done about this user’s cryptic locational declaration.
Ok, Here we go:
require(data.table)
require(ggplot2)
require(ggmap)
require(stringr)
require(twitteR)
consumer_key = mykey
consumer_secret = mysecret
access_token = mytoken
access_secret = myaccess
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
#------------------------------------------------------------------------------
#simple starter exercise:
# 1. pull twitter data on NOAA Fisheries tweets
# 2. get their locations
# 3. map them
#first just get some info on the NOAA Fisheries Twitter Account
noaa = getUser("NOAAFisheries")
location(noaa)
#use the twitteR package to pull info on all followers of
# @NOAAFisheries
noaa_follower_IDs = noaa$getFollowers(retryOnRateLimit=180)
noaa_follower_IDs = noaa$getFollowers()
length(noaa_follower_IDs)
noaa_followers_df = rbindlist(lapply(noaa_follower_IDs,as.data.frame))
#remove followers that don't report a location
noaa_followers_df = subset(noaa_followers_df, location!="")
# remove any instances of % because the geocode() function will
# not like these
noaa_followers_df$location = gsub("%", " ",noaa_followers_df$location)
#remove users whose location is some variation of USA...
# to do this I'm first going to
# strip out leading and trailing whitespace so that I don't successfully
# remove "USA" but then manage to leave in " USA"...
noaa_followers_df$location = str_trim(noaa_followers_df$location,side='both')
noaa_followers_df = noaa_followers_df[!noaa_followers_df$location %in% c("USA","U.S.A","United States","UNITED STATES")]
#confine this example to the first couple hundred followers...this is because #the geocode() function from the ggmap package only allows you to ping the API #2,500 times unless you sign on as a developer...I don't want to mess with that #at the moment so I'm
# just going to get a sample
#write a function to take a text location like "Wisconsin, USA" and turn it into #a set of lat/long coordinates. The geocode() function from the ggmap package #is used for this purpose.
geo <- function(i){
l <- noaa_followers_df$location[i]
loc <- geocode(l,output='all')
#error handling
if(is.na(loc)==T){
d.tmp <- data.frame(lat=NA,long=NA)
}else if(loc$status=='OK'){
if(length(loc[[1]])==1){
lat.tmp <- loc[[1]]
lat.tmp <- lat.tmp[[1]]$geometry
lat <- lat.tmp$location$lat
long <- lat.tmp$location$lng
d.tmp <- data.frame(lat=lat,long=long)
}else{
d.tmp <- data.frame(lat=NA,long=NA)
}
}else{
d.tmp <- data.frame(lat=NA,long=NA)
}
return(d.tmp)
}
#apply this function over the row indexes for the data frame with user
# user locations in it.
t <- Sys.time()
follower.geo <- lapply(c(1:500),geo)
Sys.time() - t
noaa.follower.geo <- data.frame(rbindlist(follower.geo))
tmp <- cbind(noaa_followers_df$location[1:500],noaa.follower.geo)
names(tmp) <- c('location','lat','long')
#now dump the lat/long from the tmp dataframe into ggmap and display a point for
#each user
map <- get_map(location = 'USA', zoom = 4)
ggmap(map) +
geom_point(aes(x = long, y = lat), data = tmp, alpha = .5, size=3)
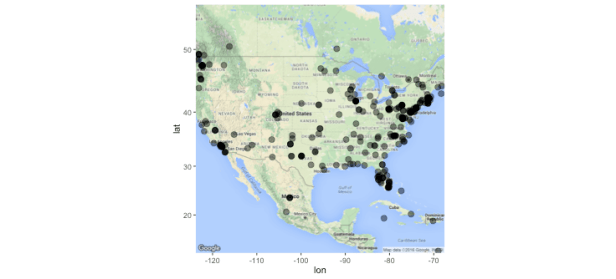
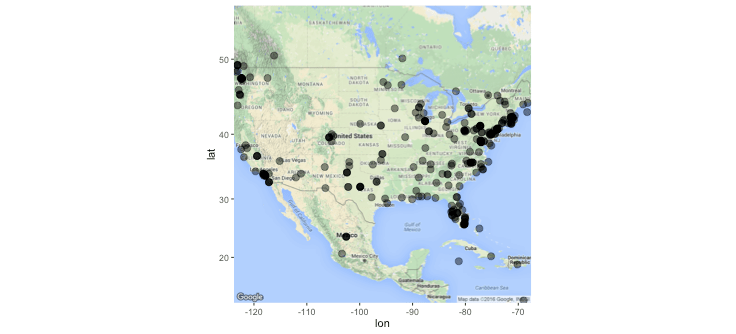
No big surprises here. Twitter users following @NOAAFisheries tend to concentrate along the coasts (places where Americans in general tend to concentrate). Although I’ll emphasize the need to exercise caution with any interpretation of this map since I only used the 1st few hundred followers…and even at that it was really only the first few hundred with valid locational info in their Twitter profile.
One thing to note about how I dealt with the locations in the script above: The geocode() function accepts an input argument ‘output’…setting this argument to ‘all’ will return location information on all matches. I found this feature helpful in filtering out ambiguous locations. For example
library(ggmap)
bad.location=geocode('paris',output='all')
length(bad.location$results)
[1] 5
Basically, asking geocode() to parse the location ‘paris’ gets you a lot of results because Google doesn’t know if you want Paris, TX, Paris, KY, Paris, France or Paris Township in Edgar County Illinois.
In my script above I just set the lat/long to NA for any entry with multiple results…I threw out anything that couldn’t be uniquely identified. There are probably more sophisticated ways of dealing with these entries.
Wrap-up
After playing around with twitteR for few hours I’m feeling like it could be a pretty powerful tool for conservation science. Obviously it has serious limitations (Twitter users may not constitute a representative sample of Americans, tweets can only be searched around a one-week window) but it definitely seems like something worth investigating further.
Here are a few things that occurred to me might be worth further investigation:
1. For protected species recovery: what content gets ‘retweeted’ or ‘favorited’ most?
- are followers more likely to respond to links to news items? or organic content?
- what keywords are followers most likely to engage with? #salmon? #whiteabalone? #speciesinthespotlight? etc.
2. I noticed that a surprising number of Twitter users following @NOAAFisheres were from places outside the United States. Currently some of our most important conservation issues involve other countries…specifically those countries with weak environmental institutions such as might prevent further decline of imperiled species. Twitter data might be an interesting way to gauge international opinion/awareness of endangered species issues.
