
The updated GitHub Repo where all this code lives is here:
https://github.com/aaronmams/cool-time-series-stuff
In my previous post I tried to layout the essential characteristics of Markov Regime Switching Models. In this post I’m going to walk through maximum likelihood estimation of parameters of a simple Markov Regime Switching Model using some roll-your-own flavor Hamilton Filter code, aided by the CRAN approved MSWM Package for estimation Regime Change Models.
The primary reason I wanted to try and do this estimation by hand is the following: I have a research question that involves monthly data on a possibly seasonal process (landings in a commercial fishery over several years) where a potentially process- altering regulatory policy was initiated at a particular time. I tried modeling this process using monthly dummy variables (to capture the seasonality) in a Markov Regime Switching Model which, I reasoned, would allow the coefficients on the monthly dummy variable to be different in different states of the system…thereby allowing for different patterns of seasonality in different regimes. In practice, the software I used to estimate the model (STATA’s mswitch and R’s MSwM) had a difficult time i) identifying regimes that looked obvious on visual inspection of the data and ii) estimating consistent parameters – consecutive runs of the model with the same data and starting values would produce different estimated coefficients.
I decided I really needed to take a few steps back and try to understand the mechanics of this model a little better in order to know whether this is the right modelling approach for my problem.
###################################################
###################################################
The Setting For This Post:
I’m going to estimate a simple 2-state Markov Switching Regression model where the price of natural gas is regressed on the price of oil. The coefficients of the model are allowed to differ depending on the state of the system. Specifically:
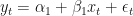

where 

This model has 8 parameters to estimate:
the regression intercepts in state 1 and state 2 respectively
the coefficients on the price of oil in states 1 and 2
the standard deviation of the residual in states 1 and 2
the transition probabilities from state 1 to state 1 and from state 2 to state 2.
This example comes from an application developed by Dr. Matt Brigida. You can follow the link to his GitHub repo or check out his paper here.
###################################################
###################################################
How the Hamilton Filter Works
Hamilton’s 1989 paper proposed an algorithm to estimate parameters of a switching process when the true state of the system at any given time is unobservable. Basically we want to jointly estimate i) the parameters of the model conditional on being in either state 1 or state 2 and ii) the probability that we are in state 1 or state 2 at a particular time.
The basic steps of the Hamilton Filter are laid out really nicely by Jim Hamilton himself in the Palgrave Dictionary of Economics, they are (note, I’m using notation from my previous post here…but the notation is consistent with Hamilton’s):
1. initialize a guess (expectation) as to the probabilities of each state in time 1,
2. use data available at time 1 to update this expectation,
3. use the transition probabilities to form an expectation about the state probabilities for time 2,
4. and so on and so forth until
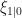
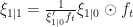


###################################################
###################################################
OK, so here’s the code
#---------------------------------------------------------------------
#use this function to get the same data that Matt Brigida uses
require(XML)
require(xts)
library(EIAdata)
getMonEIA <- function(ID, key) {
ID <- unlist(strsplit(ID, ";"))
key <- unlist(strsplit(key, ";"))
url <- paste("http://api.eia.gov/series?series_id=", ID, "&api_key=", key,
"&out=xml", sep = "")
doc <- xmlParse(file = url, isURL = TRUE)
df <- xmlToDataFrame(nodes = getNodeSet(doc, "//data/row"))
df <- plyr::arrange(df, df$date)
date <- as.Date(paste(as.character(levels(df[, 1]))[df[, 1]], "01", sep = ""),
"%Y%m%d")
values <- as.numeric(levels(df[, -1]))[df[, -1]]
tmp <- data.frame(date=date,x=values)
names(tmp) <- c('date',paste(ID))
return(tmp)
#xts_data <- xts(values, order.by = date)
#names(xts_data) <- sapply(strsplit(ID, "-"), paste, collapse = ".")
#assign(sapply(strsplit(ID, "-"), paste, collapse = "."), xts_data, envir = .GlobalEnv)
}
#----------------------------------------------------------------------
This is the code – which is really awesome in it’s own right – that Matt Brigida developed to pull energy price data directly from the EIA’s Open Data API. Check out Matt’s blog for more info on how to use this data-pull function.
In order to use Matt’s function you need to contact the EIA to get an API key. It’s free, just email them and they’ll send you one…be cool, don’t use mine, get your own.
#----------------------------------------------------------------------------------- #in order to pull the data we will need to provide a key. The EIA will send you a key for # accessing their open data API....details can be found here: #http://complete-markets.com/2014/01/r-functions-to-interact-with-the-eias-application-programming-interface-api/ key <- '80DAEF6FDCF88254A3D4E2F5F4CBF99C' #-----------------------------------------------------------------------------------
Next, I use Matt’s function to pull monthly prices for Natural Gas and West Texas Crude:
#-----------------------------------------------------------------------------------
# use the function above to get monthly data from the EIA on natural gas prices and West
# Texas Crude Oil...then filter the series so they are the same length
lng <- getMonEIA(ID='NG.RNGWHHD.M',key=key)
names(lng) <- c('date','lng')
oil <- getMonEIA(ID='PET.RWTC.M',key=key)
names(oil) <- c('date','oil')
start <- max(c(min(lng$date),min(oil$date)))
end <- min(max(lng$date),max(oil$date))
lnoil <- log(as.vector(oil$oil[which(oil$date>=start & oil$date<=end)]))
lnng <- log(as.vector(lng$lng[which(lng$date>=start & lng$date<=end)]))
#-----------------------------------------------------------------------------------
Now that I have the data, I’m going to write a function to execute the Hamilton Filter. The function takes 3 inputs:
- ‘theta’ – this is the parameter vector…In my case it should have 8 elements. The Hamilton Filter is going to construct a log likelihood function and inference about the probabilities of being in each of the two states at any give time, conditional on the parameter values. The reason we are writing this as an R function is so we can optimize the function to get the maximum likelihood parameter values.
- y – this is the dependent variable in the model…in this case, the monthly prices for natural gas.
- x – this is the independent variable in the model…in this case, the monthly prices for West Texas Crude.
################################################################################
################################################################################
################################################################################
# The Hamilton Filter
#need to write a function to do the calculation then optimize that function
#NOTE: this is not all that general. It is set up to deal with a simple univariate
# regression model where:
# y(t) = alpha1 + beta1*x(t) if we are in regime 1
# y(t) = alpha2 + beta2*x(t) if we are in regime 2
# we need to generalize this later to be amenable to different regression forms
mrs.est <- function(theta,x,y){
alpha1 <- theta[1]
alpha2 <- theta[2]
alpha3 <- theta[3]
alpha4 <- theta[4]
alpha5 <- theta[5]
alpha6 <- theta[6]
p11 <- 1/(1+exp(-theta[7]))
p22 <- 1/(1+exp(-theta[8]))
#in order to make inference about what state we are in in period t we need the conditional
# densities given the information set through t-1
f1 <- (1/(alpha5*sqrt(2*pi)))*exp(-((y-alpha1-(alpha3*x))^2)/(2*(alpha5^2)))
f2 <- (1/(alpha6*sqrt(2*pi)))*exp(-((y-alpha2-(alpha4*x))^2)/(2*(alpha6^2)))
f <- matrix(cbind(f1,f2),nc=2)
#S.forecast is the state value looking forward conditional on info up to time t
#S.inf is the updated state value
S.forecast <- rep(0,2*length(y))
S.forecast <- matrix(S.forecast,nrow=(length(y)),ncol=2)
S.inf <- S.forecast
o.v <- c(1,1)
P<-matrix(c(p11,(1-p11),(1-p22),p22),nr=2,nc=2)
model.lik <- rep(0,length(y))
S.inf[1,] <- (c(p11,p22)*f[1,])/(o.v %*% (c(p11,p22)*f[1,]))
for(t in 1:(length(y)-1)){
#in time t we first make our forecast of the state in t+1 based on the
# data up to time t, then we update that forecast based on the data
# available in t+1
S.forecast[t+1,] <- P%*%S.inf[t,]
S.inf[t+1,] <- (S.forecast[t+1,]*f[t+1,])/(S.forecast[t+1,] %*% f[t+1,])
model.lik[t+1] <- o.v%*%(S.forecast[t+1,]*f[t+1,])
}
logl <- sum(log(model.lik[2:length(model.lik)]))
return(-logl)
}
################################################################################
################################################################################
################################################################################
Two things are particularly worth noting here:
- The model uses transformed transition probabilities. Note lines 24 and 25 in the code above have the transformation
. This transformation allows the
elements of the vector
to be real-valued and allows us to use unconstrained optimization to maximize the likelihood function. Matt Brigida pointed this out to me and I’ll be forever grateful as it saved me a ton of time.
- I favor the recursive strategy of projecting forward to time
from time
but there is no reason why you couldn’t run the filter from 2:length(y) instead, doing the updating in
.
Next, we write a function to get smoothed probabilities. The Hamilton Filter yeilds filtered probabilities, i.e. the probability that we are in state 1 in time 
This is accomplished by:
- running the Hamilton Filter once using the maximum likelihood parameter estimates and saving the forecasted state probabilities at each time-step.
- running the filter once more in reverse ‘backwards updating’ at each time-step to take advantage of all information in the time-series
################################################################################
################################################################################
################################################################################
#The Hamilton Smoother: the smoothed probabilities are obtained by:
#1. using the Hamilton Filter to get maximum likelihood parameter estimates
#2. using the maximum likelihood parameter estimates to run the Filter again...
#2a but in the smoothing step we work from T-1 back to t=1
#==============================================================
#==============================================================
#to get the smoothed probabilities we run the filter again using
# the maximum likelihood values but we need to save both the
# forecasted state probabilities (St given info in t-1) and
# the updated state probabilities (St updated to reflect info in time t)
#=================================================================
#=================================================================
#get the maximum likelihood estimates
ham.smooth<-function(theta,y,x){
alpha1 <- theta[1]
alpha2 <- theta[2]
alpha3 <- theta[3]
alpha4 <- theta[4]
alpha5 <- theta[5]
alpha6 <- theta[6]
# p11 <- 1/(1+exp(-theta[7]))
# p22 <- 1/(1+exp(-theta[8]))
p11 <- theta[7]
p22 <- theta[8]
#in order to make inference about what state we are in in period t we need the conditional
# densities given the information set through t-1
f1 <- (1/(alpha5*sqrt(2*pi)))*exp(-((y-alpha1-(alpha3*x))^2)/(2*(alpha5^2)))
f2 <- (1/(alpha6*sqrt(2*pi)))*exp(-((y-alpha2-(alpha4*x))^2)/(2*(alpha6^2)))
f <- matrix(cbind(f1,f2),nc=2)
#S.forecast is the state value looking forward conditional on info up to time t
#S.inf is the updated state value
S.forecast <- rep(0,2*length(y))
S.forecast <- matrix(S.forecast,nrow=(length(y)),ncol=2)
S.inf <- S.forecast
o.v <- c(1,1)
P<-matrix(c(p11,(1-p11),(1-p22),p22),nr=2,nc=2)
model.lik <- rep(0,length(y))
S.inf[1,] <- (c(p11,p22)*f[1,])/(o.v %*% (c(p11,p22)*f[1,]))
for(t in 1:(length(y)-1)){
#in time t we first make our forecast of the state in t+1 based on the
# data up to time t, then we update that forecast based on the data
# available in t+1
S.forecast[t+1,] <- P%*%S.inf[t,]
S.inf[t+1,] <- (S.forecast[t+1,]*f[t+1,])/(S.forecast[t+1,] %*% f[t+1,])
model.lik[t+1] <- o.v%*%(S.forecast[t+1,]*f[t+1,])
}
#the smoother works kind of like running the filter in reverse
# we start with the last value of S from the filter recursion...
# this is the value of S in the last period, updated to reflect
# information available in that period...we then work backwards from
# there
T<- length(y)
P.smooth <- data.frame(s1=rep(0,T),s2=rep(0,T))
P.smooth[T,] <- S.inf[T,]
for(is in (T-1):1){
#for clarify we can think of this problem has having 4 states...
#note we word these as current period and next period because
# the smoother works from T back to 1
#1. probability that we observe S(t)=1, S(t+1)=1
#2. probability that we observe S(t)=1, S(t+1)=2
#3. probability that we observe S(t)=2, S(t+1)=1
#4. probability that we observe S(t)=2, S(t+1)=2
#for #1 P[S(t)=1,S(t+1)=1|I(t+1)] = {P[S(t+1)=1|I(t+1)]*P[S(t)=1|I(t)]*P[S(t+1)=1|S(t)=1]}/P[S(t+1)=1|I(t)]
p1 <- (S.inf[is+1,1]*S.inf[is,1]*p11)/S.forecast[is+1,1]
#for #2 we have
p2 <- (S.inf[is+1,2]*S.inf[is,1]*(1-p11))/S.forecast[is+1,2]
#for #3 we have
p3 <- (S.inf[is+1,1]*S.inf[is,2]*(1-p22))/S.forecast[is+1,1]
#for #4 we have
p4 <- (S.inf[is+1,2]*S.inf[is,2]*p22)/S.forecast[is+1,2]
P.smooth[is,1] <- p1 + p2
P.smooth[is,2] <- p3 + p4
}
return(P.smooth)
}
#==========================================================
The function ham.smooth produces a data frame of smoothed probabilities for each time period.
###################################################
###################################################
###################################################
###################################################
OK, now for some testing
One way I devised to figure out if my code was any good was to compare it to some stuff that has at least been vetted enough to be distributed through CRAN. The problem with direct comparison of parameters across different Markov Switching Models is that all recursive algorithms are kind of sensitive to local optima and starting values. So I decided to compare my smoothing algorithm with the Smoothed Probabilities from the MSwM package.
To do this I first ran the MSwM parameter estimation, then I plugged the resulting parameter estimates into my smoother to see if, given the same likelihood maximizing parameters, my smoother would produce the same smoothed state probabilities as the MSwM package.
#-------------------------------------------------------------------
#first I'm going to QA my smoother by comparing smoothed state
# probabilities from my approach versus the MSwM package. To do
# this I need to run the filter using the same estimated parameters
# that the MSwM gets
mod1 <- lm(lnng~lnoil)
mod1.mswm <- msmFit(mod1,k=2,p=0,sw=rep(TRUE,3),control=list(parallel=F))
summary(mod1.mswm)
dev.off()
plotProb(mod1.mswm,which=2)
sigma.mswm <- mod1.mswm@std
theta.smooth <- c(mod1.mswm@Coef[1,1],mod1.mswm@Coef[2,1],mod1.mswm@Coef[1,2],mod1.mswm@Coef[2,2],sigma.mswm,
mod1.mswm@transMat[1,1],mod1.mswm@transMat[2,2])
tmp <- ham.smooth(theta=theta.smooth,y=lnng,x=lnoil)
tmp$t <- seq(1:nrow(tmp))
tmp$model="Mams"
mswm.smooth <- data.frame(mod1.mswm@Fit@smoProb[2:nrow(mod1.mswm@Fit@smoProb),])
names(mswm.smooth) <- c('s1','s2')
mswm.smooth$t <- seq(1:nrow(mswm.smooth))
mswm.smooth$model <- 'MSwM'
tmp <- rbind(tmp,mswm.smooth)
ggplot(tmp,aes(x=t,y=s2,color=model)) + geom_line(size=1) +
ylab("Smoothed Probability of Regime 2") + theme_bw()
#---------------------------------------------------------------------
######################################################################
And the resulting plot:

Not bad…not sure why mine smooths out that little spike around t=150 but I’m working on it.
###################################################
###################################################
###################################################
###################################################
