Base R has functions for running compiled C and Fortran code (‘.C’, ‘.Cpp’ and ‘.Fortran’). I occasionally have a use for such functionality…typically when I’m dealing with certain numerical methods that tend to be loop-intensive. As with all things R, there are some pretty solid tutorials out there on running compiled code in R. Peng and de Leew have a good one for the .C interface and this one from the stats department at University of Minnesota are two that I found reasonably easy to follow. Though I found the information in these online tutorials comprehensive and easy to follow, almost all of the online resource I found on the .Fortran interface for R were missing various small (but not insignificant) details on the process. So this post is dedicated to walking step-by-step through the process of running some Fortran subroutines I have for carrying out function approximation using orthogonal Chebyshev polynomials.
Approximation of an unknown function using Chebyshev Polynomials is one example of a loop-intensive undertaking that runs much faster from compiled code than from within R.
Some basic background
Chebyshev polynomials are one family of orthogonal polynomials which turn out to be quite useful in function approximation. Chebyshev polynomials satisfy the following recursive scheme:

I have neither the inclination nor the chops to engage you all in a lengthy discussion of approximation theory. I’m generally a consumer (not a producer) of approximation algorithms…but I understand the basics which are that Chebyshev approximation creates a weighted sum of polynomials with different curvatures. Like most approximation schemes, the weights (or coefficients) determine how important the value of the function at a known point is in determining the function ‘guess’ at an unknown point. By including polynomials of various orders, a Chebyshev algorithm can provide a good approximation to many types of unknown functions.
Before going any further let me answer a few questions readers are likely to have:
What are some uses of Chebyshev Function Approximation?
While I have a vague sense that physical scientists use orthogonal polynomials in general, and Chebyshev polynomials in particular, I honestly couldn’t tell you what they do with them. I can tell you that I find Chebyshev approximation to be extremely helpful in solving dynamic optimization problems. Dynamic programming with a backwards-induction algorithm often involves creating an n-dimensional grid (n being the dimensionality of the state space) spanning the state space. Efficient evaluation of the value function generally proceeds by evaluating the value function at a set of grid points (nodes) and interpolating/approximating values for points in between nodes.
I use Chebyshev polynomials for this approximation because:
1. They’re fast
2. It is straightforward to recover, not only the function approximation, but the derivatives as well…which are generally quite useful in speeding up numerical work,
Although many technical programming platforms have built-in function approximation/interpolation routines, I have found that recovering the derivatives at the point of approximation can be trickier with canned routines.
Why use Fortran?
Recursive algorithms (be they Chebyshev Polynomial Approximation or Dynamic Programming with backwards recursion) are loop intensive. This is the type of thing that Fortran and C are good at.
Why run Fortran through R?
If you’re a Fortran junkie I’m not here to talk you into a different workflow. I like R for managing large programs or simulation because I can take advantage of what R does well (lots of packages and built-in functions for doing shit I don’t want to write by hand) and still take advantage of what Fortran does well (runs loops super-fast).
The Chebyshev Algorithm
For this example I’m going to stick close to Ken Judd’s treatment of Chebyshev Approximation in 2 dimensions. The following is from Numerical Methods in Economics by Kenneth Judd, pg. 238.
Objective: Given a function 
![[a,b]X[c,d]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5DX%5Bc%2Cd%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
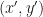
Step 1: Compute the 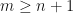
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)

Step 2: Adjust the nodes to the ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
![[c,d]](https://s0.wp.com/latex.php?latex=%5Bc%2Cd%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)


Step 3: Evaluate 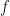

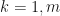

Step 4: Compute the Chebyshev coefficients
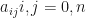

To compute the approximation of
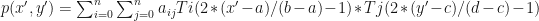
The Fortran Routines
I’ve split the algorithm above into 3 Fortran subroutines (chebnodes, chebceoff, and chebeval2).
The first subroutine, chebnodes, forms the nodes for Chebyshev interpolation corresponding to Step 2 above.
subroutine chebnodes(xmin, xmax, mx,x)
integer i, mx
double precision xmin, xmax
double precision ctr
double precision rng
double precision tmp
double precision x(mx)
REAL, PARAMETER :: Pi = 3.1415927
ctr = (xmin + xmax)*0.5
rng = (xmax - xmin)*0.5
do 100 i = 1, mx
x(i) = ctr - rng*cos( (i - 0.5)*Pi/mx )
100 continue
end
Now we get to some meaty stuff. Having written this subroutine in TextWrangler and saved it as “Users/aaronmamula/Documents/chebnodes.f”, I need to compile it. Important note: I’m using the free Fortran compiler for MacOS gfortran, running from gcc version 4.2.3.
For reasons which I suspect are related to my fortran compiler really wanting there to be a subroutine called “main”, I’m not able to compile my chebnodes subroutine using
gfortran -o chebnodes.f chebnodes
…which isn’t a problem for me currently because I really just want the subroutine available as a shared library for use in R. From the terminal I compile to a shared library with,
R CMD SHLIB chebnodes.f
This creates a .so (chebnodes.so) file in the current directory. To load this subroutine into the R workspace we use the command “dyn.load”,
setwd("/Users/aaronmamula/Documents")
dyn.load("chebnodes.so")
Now the chebnodes subroutine is available for use in our R session. To use it we simply send it some values through a call to .Fortran and the subroutine makes some changes to those values and send them back. In this specific case we are going to create two 1-dimensional interpolation grids, an x-grid with 6 nodes and a y-grid with 9 nodes.
xmin <- 1
xmax <- 2
m.x <- c(6,9)
ymin <- 15
ymax <- 20
x <- rep(0,m.x[1])
x.nodes <- .Fortran("chebnodes",
xmin=as.double(xmin),
xmax=as.double(xmax),
mx = as.integer(m.x[1]),
x=as.double(x)
)
y <- rep(0,m.x[2])
y.nodes <- .Fortran("chebnodes",
xmin = as.double(ymin),
xmax = as.double(ymax),
mx = as.integer(m.x[2]),
x = as.double(y)
)
Essentially, all that has happened here is that I’ve sent a vector of zeros to my chebnodes subroutine along with some parameter values and the call to .Fortran has returned the Chebyshev interpolation nodes in the x dimension.
The next step in our approximation is to compute the Chebyshev coefficients. Here I should point out that I’ve chosen to be very explicit about reflecting Judd’s algorithm in the code. The subroutine below can be condensed considerably using the identity that

Note that the trigonometric expression for the 

Also note that
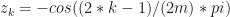
Next, let

Now,
![T_n(z_k) = cos(n*acos(-cos(y))) = cos( n* [pi - acos(cos(y))] = cos (n*(pi - y))](https://s0.wp.com/latex.php?latex=T_n%28z_k%29+%3D+cos%28n%2Aacos%28-cos%28y%29%29%29+%3D+++++cos%28+n%2A+%5Bpi+-+acos%28cos%28y%29%29%5D+%3D+cos+%28n%2A%28pi+-+y%29%29&bg=%23ffffff&fg=%23111111&s=0&c=20201002)

![T_n(z_k) = cos(n*(pi[1-(2k/2m)+(1/2m)])](https://s0.wp.com/latex.php?latex=T_n%28z_k%29+%3D+cos%28n%2A%28pi%5B1-%282k%2F2m%29%2B%281%2F2m%29%5D%29&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
![T_n(z_k) = cos(n*(pi[(2m/2m) - (2k/2m) + (1/2m)])](https://s0.wp.com/latex.php?latex=T_n%28z_k%29+%3D+cos%28n%2A%28pi%5B%282m%2F2m%29+-+%282k%2F2m%29+%2B+%281%2F2m%29%5D%29&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
![T_n(z_k) = cos(n*((pi/m)*[m-k+0.5]))](https://s0.wp.com/latex.php?latex=T_n%28z_k%29+%3D+cos%28n%2A%28%28pi%2Fm%29%2A%5Bm-k%2B0.5%5D%29%29&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
subroutine chebcoeff(mx, my, zx, zy, ypts, coef)
implicit double precision (a-h,o-z)
parameter (ndim=2,pi=3.141592653589793d0)
double precision coef(1:mx,1:my)
double precision ypts(1:mx,1:my)
double precision phi1,phi2,denom
double precision zx(1:mx), zy(1:my)
integer mx, my
double precision Ti(1:mx,1:mx), Tj(1:my,1:my)
double precision sum, sumb1, sumb2
!populate a matrix of chebyshev polynomials
do 10 i1= 1, mx
do 20 i2 = 1, mx
Ti(i2,1) = 1
Ti(i2,2)=zx(i2)
if(i1.gt.2) Ti(i2,i1)=2*zx(i2)*Ti(i2,i1-1) - Ti(i2,i1-2)
20 continue
10 continue
do 30 j1= 1, my
do 40 j2 = 1, my
Tj(j2,1) = 1
Tj(j2,2)= zy(j2)
if(j1.gt.2) Tj(j2,j1)=2*zy(j2)*Tj(j2,j1-1) - Tj(j2,j1-2)
40 continue
30 continue
do ii1 = 1, mx
do ii2 = 1, my
coef(ii1,ii2) = 0
phi1 = 0
do ik = 1, mx
phi2 = 0
phi1 = phi1 + (Ti(ik,ii1)*Ti(ik,ii1))
do il = 1, my
phi2 = phi2 + (Tj(il,ii2)*Tj(il,ii2))
coef(ii1,ii2) = coef(ii1,ii2) + ypts(ik,il)*Ti(ik,ii1)*Tj(il,ii2)
enddo
enddo
coef(ii1,ii2)=coef(ii1,ii2)/(phi1*phi2)
enddo
enddo
end
The chebcoeff subroutine is a function of the same parameters we used to created the interpolation nodes in the x and y dimensions, plus the function values at those nodes. The following R code calculates the chebyshev coefficients:
#load the chebcoeff subroutine
dyn.load("chebycoeff.so")
#establish the function and evaluate the function
#at the x-y interpolation nodes
f <- function(x) log(x[[1]])*sqrt(x[[2]])/log(sum(x))
w <- matrix(0,nr=m.x[1],nc=m.x[2])
for(ik in 1:m.x[1]){
xk <- x.nodes$x[ik]
for(il in 1:m.x[2]){
yl <- y.nodes$x[il]
w[ik,il] <- f(c(xk,yl))
}
}
#Compute Chebyshev coefficients
ypts <- w
coef <- matrix(0,nr=m.x[1],nc=m.x[2])
z <- .Fortran("chebcoeff", mx=as.integer(m.x[1]), my=as.integer(m.x[2]),
zx = as.array(z1),zy = as.array(z2),
ypts = as.array(ypts),
coef = as.array(coef)
)
The final step is the approximation of the function, 
subroutine chebeval2(xmin, xmax, mx, my, x, chebcoef,p)
!INPUTS:
!xmin,xmax: arrays(ndim X 1). upper and lower bounds of
! of the function space in each dimension
!mx,my : scalar. maximum degree of interpolating
! polynomial in each dimension.
!x : array(ndim X 1). (x,y) values at which to
! approximate the function
!chebcoef : array(1:mx,1:my) values of the chebyshev coefficients
!p : scalar.
parameter (ndim=2)
integer i,j,n
double precision xmin(ndim), xmax(ndim), x(ndim)
integer mx
double precision a,b,c,d,p,z1,z2
double precision chebcoef(1:mx,1:my), result(1:mx,1:my)
double precision Ti(1:mx), Tj(1:my)
a = xmin(1)
b = xmax(1)
c = xmin(2)
d = xmax(2)
xx = x(1)
yy = x(2)
! y = (2 * ( (x - xmin)/(xmax - xmin) )) - 1
z1 = (2 * (xx-a)/(b-a)) - 1
z2 = (2 * (yy-c)/(d-c)) - 1
p = 0.0d0
do 10 i=1,mx
Ti(1) = 1
Ti(2) = z1
if(i.gt.2) Ti(i) = 2*z1*Ti(i-1) - Ti(i-2)
do 20 j=1,my
Tj(1) = 1
Tj(2) = z2
if(j.gt.2) Tj(j) = 2*z2*Tj(j-1) - Tj(j-2)
p = p + (chebcoef(i,j)*Ti(i)*Tj(j) )
20 continue
10 continue
end
And finally, the R code to invoke chebeval2:
xhat <- c(1.498965,18.19821)
chebcoef <- z$coef
eval <- .Fortran("chebeval2",
xmin=as.array(xmin),
xmax=as.array(xmax),
mx=as.integer(6),
my = as.integer(9),
x=as.array(x),
chebcoef=as.array(chebcoef),
p = as.double(0))
To wrap-up let’s go step-by-step through the process of approximating the function 
1. The first step is to compile each of the necessary fortran subroutines to a shared library. From the terminal:
cd "/Users/aaronmamula/Documents" R CMD SHLIB chebnodes.f R CMD SHLIB chebcoeff.f R CMD SHLIB chebeval2.f
2. Next load the .so files into the R workspace:
setwd("Users/aaronmamula/Documents")
dyn.load("chebnodes.so")
dyn.load("chebcoeff.so")
dyn.load("chebeval2.so)
3. Set up R code to pass necessary parameters to Fortran subroutines and collect output:
xmin <- 1
xmax <- 2
ymin <- 15
ymax <- 20
m.x <- c(6,9)
m.y <- 9
x <- rep(0,m.x[1])
x.nodes <- .Fortran("chebnodes", xmin=as.double(xmin), xmax=as.double(xmax), mx=as.integer(m.x[1]),x=as.double(x))
> x.nodes
$xmin
[1] 1
$xmax
[1] 2
$mx
[1] 6
$x
[1] 1.017037 1.146447 1.370591 1.629410 1.853553 1.982963
y <- rep(0,m.y)
y.nodes <- .Fortran("chebnodes",xmin=as.double(ymin),xmax=as.double(ymax),mx=as.integer(m.x[2]),x=as.double(y))
> y.nodes
$xmin
[1] 15
$xmax
[1] 20
$mx
[1] 9
$x
[1] 15.03798 15.33494 15.89303 16.64495 17.50000 18.35505 19.10697 19.66506 19.96202
f <- function(x) log(x[[1]])*sqrt(x[[2]])/log(sum(x))
w <- matrix(0,nr=m.x[1],nc=m.x[2])
for(ik in 1:m.x[1]){
xk <- x.nodes$x[ik]
for(il in 1:m.x[2]){
yl <- y.nodes$x[il]
w[ik,il] <- f(c(xk,yl))
}
}
#Compute the mx X my matrix of chebyshev coefficients
ypts <- w
coef <- matrix(0,nr=m.x[1],nc=m.x[2])
z1 <- matrix(0,nr=m.x[1],nc=1)
for(iz in 1:m.x[1]){
z1[iz] <- -cos((((2*iz)-1)/(2*m.x[1]))*pi)
}
z2 <- matrix(0,nr=m.x[2],nc=1)
for(iz in 1:m.x[2]){
z2[iz] <- -cos((((2*iz)-1)/(2*m.x[2]))*pi)
}
z <- .Fortran("chebcoeff", mx=as.integer(m.x[1]), my=as.integer(m.x[2]),
zx = as.array(z1),zy = as.array(z2),
ypts = as.array(ypts),
coef = as.array(coef)
)
z$ypts
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] 0.02359902 0.02367458 0.02381551 0.0240031 0.02421324 0.02442002 0.02459913 0.02473044 0.02479975
[2,] 0.19036289 0.19098597 0.19214680 0.1936899 0.19541609 0.19711243 0.19858016 0.19965539 0.20022268
[3,] 0.43693933 0.43842180 0.44117949 0.4448376 0.44892038 0.45292421 0.45638253 0.45891285 0.46024686
[4,] 0.67292780 0.67530070 0.67970802 0.6855420 0.69203804 0.69839487 0.70387585 0.70788088 0.70999071
[5,] 0.84655756 0.84963717 0.85535042 0.8629008 0.87129313 0.87949200 0.88655149 0.89170473 0.89441777
[6,] 0.93660983 0.94007584 0.94650203 0.9549873 0.96441001 0.97360737 0.98152075 0.98729419 0.99033274
z$coef
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 5.324759e-01 1.463415e-02 -2.395350e-04 6.940044e-06 -2.462999e-07 1.018064e-08 -1.767332e-10
[2,] 4.827531e-01 1.372835e-02 -2.476478e-04 8.508096e-06 -3.853171e-07 2.103942e-08 -1.008526e-09
[3,] -4.398219e-02 -7.994950e-04 -6.935017e-06 1.345167e-06 -1.181577e-07 9.127580e-09 -6.918298e-10
[4,] 4.998428e-03 9.188437e-05 1.070873e-06 -1.971216e-07 1.834659e-08 -1.516406e-09 1.220816e-10
[5,] -6.395552e-04 -1.236678e-05 -9.674652e-08 2.260335e-08 -2.199065e-09 1.877977e-10 -1.561765e-11
[6,] 8.574944e-05 1.707195e-06 8.934092e-09 -2.685397e-09 2.663259e-10 -2.291214e-11 1.921475e-12
[,8] [,9]
[1,] 1.859039e-10 -3.531716e-10
[2,] 2.357322e-10 -3.360740e-10
[3,] 4.024931e-11 1.540858e-11
[4,] -8.325659e-12 -1.458884e-12
[5,] 1.096450e-12 1.957806e-13
[6,] -1.337099e-13 -2.835026e-14
#Use the parameters plus the Chebyshev coefficients to evaluate the function at #the test point (x=1.498965, y=18.19821)
x <- matrix(c(1.498965,18.19821),nr=2,nc=1)
chebcoef <- z$coef
eval <- .Fortran("chebeval2",
xmin=as.array(c(xmin,ymin),nr=2,nc=1),
xmax=as.array(c(xmax,ymax), nr=2, nc=1),
mx=as.integer(6),
my = as.integer(9),
x=as.array(x),
chebcoef=as.array(chebcoef),
p = as.double(0))
> f.test(c(xhat,yhat))
[1] 0.5793518
> eval$p
[1] 0.5793398
A final word: my choice of function to approximate and test point to use was not arbitrary. In the documentation for the R package chebpol, the authors test their Chebyshev approximation routine using the function and test points stated above.

).svg){kind=link}